Author’s Note: this is just a quick post about an engineering hiccup we ran into while implementing HyperLogLog features that aren’t mentioned in the original paper. We have an introduction to the algorithm and several other posts on the topic if you’re interested.
Say you had two HyperLogLog data structures with 5-bit-wide registers, one with 


If you imagine feeding the same element into an HLL of the smaller size, then the 4 bits you truncated from the index would have actually been used in the computation of the register value.

You couldn’t simply take the original register value you computed, you’d have to take into account the new prefix added to the register value bit string. If the prefix has a 1 in it, you would recompute the run of zeroes on just the prefix (because you know it contains a 1 and thus all the information you need), and if not, you’d add the length of the prefix to the original register value computed. Not a ton of work, but having clutter like this in algorithmic code distracts the reader from the true intention. So how do we avoid this?
Well, you could say that it’s very, very unlikely that you’ll ever need more than 30 bits for your register value, so you could assume that the register width would remain constant forever and use the bottom 30 bits for your register value and the next 

Now you can just truncate the register index and use the original register value.

If you’re using a good hash function like MurmurHash3 that gives you 128 bits of entropy, you could simply compute the register index from the first 64-bit word in the hash and compute the register value from the second 64-bit word and completely ignore this problem up to a mind-bending 
I know it’s not always possible to anticipate this problem in the early stages of implementing and vetting an algorithm, but hopefully with a bit of research the next time someone looks to implement HLL they’ll see this and learn from our mistake.
 is greater than
is greater than  . In this regime, they replace the usual HLL estimate by the estimate
. In this regime, they replace the usual HLL estimate by the estimate .
. -bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate
-bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate  empty bins. The number of empty bins should be about
empty bins. The number of empty bins should be about  , where
, where  is the number of balls. Hence
is the number of balls. Hence  . Solving this gives us the formula he recommends using:
. Solving this gives us the formula he recommends using:  .
. ,
, is the number of bins and
is the number of bins and  as
as  .
. as you can see
as you can see  , where
, where  represents
represents  , against the line
, against the line  . The difference between the two graphs represents the difference between
. The difference between the two graphs represents the difference between 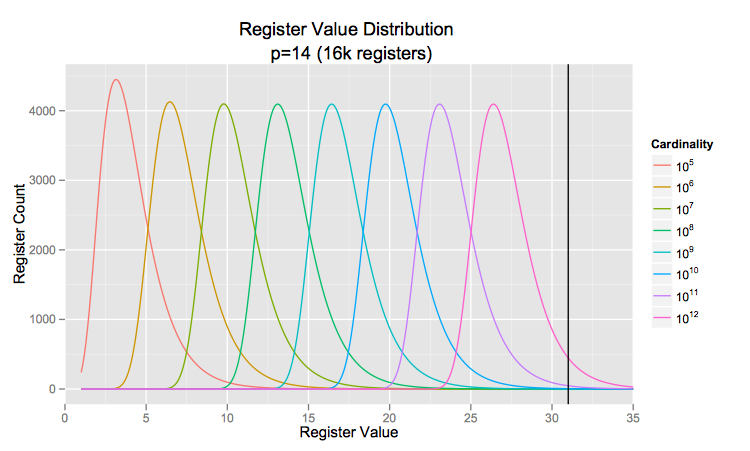
 .
. . Let’s says we wanted to safely count into the 100 billion range. If we have
. Let’s says we wanted to safely count into the 100 billion range. If we have  then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at
then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at  the large range correction only kicks in at a little under 100 billion!
the large range correction only kicks in at a little under 100 billion!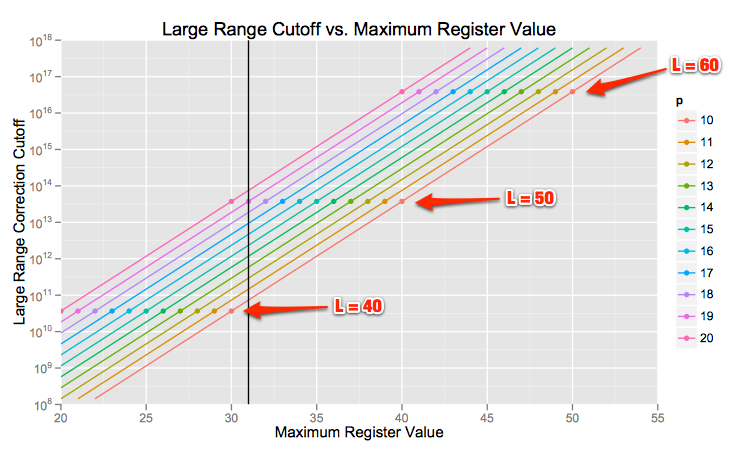
 configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space.
configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space. , for 200 values less than
, for 200 values less than  with a correction to the overestimate of
with a correction to the overestimate of 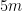 cardinality range (cuts 95th percentile relative error from about 2% to 1.2%).
cardinality range (cuts 95th percentile relative error from about 2% to 1.2%). . (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “
. (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “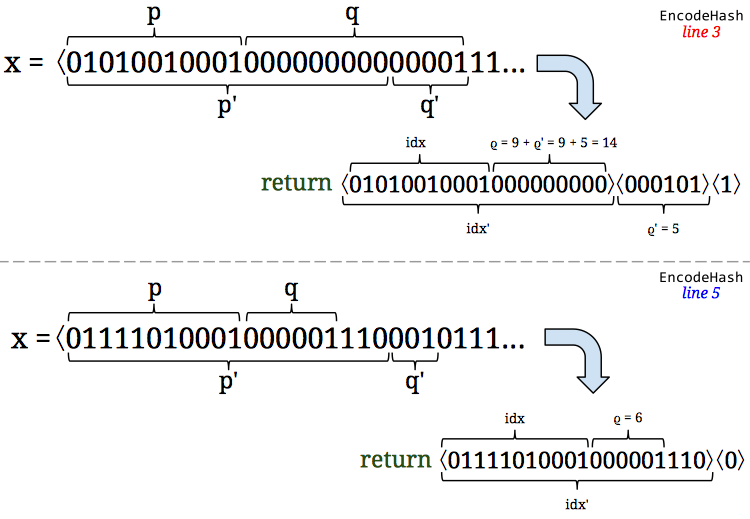
 are as in the Google paper, and
are as in the Google paper, and  and
and  are the number of bits that need to be examined to determine
are the number of bits that need to be examined to determine  for either the
for either the 
 is the register value and
is the register value and  is the number of (distinct) elements a register has seen.
is the number of (distinct) elements a register has seen. and say we insert
and say we insert 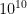 distinct elements. That means, any given register will see about
distinct elements. That means, any given register will see about  elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
 . So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,
. So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,  .
. and
and .
.![[15,40]](https://s0.wp.com/latex.php?latex=%5B15%2C40%5D&bg=ffffff&fg=000&s=0&c=20201002) . Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers.
. Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers.