Rob, Matt, and I just wrapped up our trip to Copenhagen for the EADS Summer School on Hashing at the University of Copenhagen and it was a blast! The lineup of speakers was, simply put, unbeatable: Rasmus Pagh, Graham Cormode, Michael Mitzenmacher, Mikkel Thorup, Alex Andoni, Haim Kaplan, John Langford, and Suresh Venkatasubramanian. There’s a good chance that any paper you’ve read on hashing, sketching, or streaming has one of them as a co-author or is heavily influenced by their work. The format was three hour-and-a-half lectures for four days, with exercises presented at the end of each lecture. (Slides can be found here. They might also post videos. UPDATE: They’ve posted videos!)
Despite the depth of the material, almost all of it was approachable with some experience in undergraduate math and computer science. We would strongly recommend both of Michael Mitzenmacher’s talks (1, 2) for an excellent overview of Bloom Filters and Cuckoo hashing that are, in my opinion, significantly better and more in depth than any other out there. Specifically, the Bloom Filter talk presents very elegantly the continuum of Bloom Filter to Counting Bloom Filter to Count-Min Sketch (with “conservative update”) to the Stragglers Problem and Invertible Bloom Filters to, finally, extremely recent work called Odd Sketches.
Similarly, Mikkel Thorup’s two talks on hashing (1, 2) do a very thorough job of examining the hows and whys of integer hashing, all the way from the simplest multiply-mod-prime schemes all the way to modern work on tabulation hashing. And if you haven’t heard of tabulation hashing, and specifically twisted tabulation hashing, get on that because (1) it’s amazing that it doesn’t produce trash given how simple it is, (2) it’s unbelievably fast, and (3) it has been proven to provide the guarantees required for almost all of the interesting topics we’ve discussed on the blog in the past: Bloom Filters, Count-Min sketch, HyperLogLog, chaining/linear-probing/cuckoo hash tables, and so on. We really appreciated how much attention Mikkel devoted to practicality of implementation and to empirical performance when discussing hashing algorithms. It warms our heart to hear a leading academic in this field tout the number of nanoseconds it takes to hash an item as vocally as the elegance of the proof behind it!
We love this “Summer School” format because it delivers the accumulated didactic insight of the field’s top researchers and educators to both old techniques and brand new ones. (And we hope by now that everyone reading our blog appreciates how obsessed we are with teaching and clarifying interesting algorithms and data structures!) Usually most of this insight (into origins, creative process, stumbling blocks, intermediate results, inspiration, etc.) only comes out in conversation or lectures, and even worse is withheld or elided at publishing time for the sake of “clarity” or “elegance”, which is a baffling rationale given how useful these “notes in the margin” have been to us. The longer format of the lectures really allowed for useful “digressions” into the history or inspiration for topics or proofs, which is a huge contrast to the 10-minute presentations given at a conference like SODA. (Yes, obviously the objective of SODA is to show a much greater breadth of work, but it really makes it hard to explain or digest the context of new work.)
In much the same way, the length of the program really gave us the opportunity to have great conversations with the speakers and attendees between sessions and over dinner. We can’t emphasize this enough: if your ambition to is implement and understand cutting edge algorithms and data structures then the best bang for your buck is to get out there and meet the researchers in person. We’re incredibly lucky to call most of the speakers our friends and to regularly trade notes and get pointers to new research. They have helped us time and again when we’ve been baffled by inconsistent terminology or had a hunch that two pieces of research were “basically saying the same thing”. Unsurprisingly, they are also the best group of people to talk to when it comes to understanding how to foster a culture of successful research. For instance, Mikkel has a great article on how to systematically encourage and reward research article that appears in the March 2013 issue of CACM (pay-wall’d). Also worthwhile is his guest post on Bertrand Meyer’s blog.
If Mikkel decides to host another one of these, we cannot recommend attending enough. (Did we mention it was free?!) Thanks again Mikkel, Rasmus, Graham, Alex, Michael, Haim, and John for organizing such a great program and lecturing so eloquently!


 is greater than
is greater than  . In this regime, they replace the usual HLL estimate by the estimate
. In this regime, they replace the usual HLL estimate by the estimate .
. -bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate
-bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate  empty bins. The number of empty bins should be about
empty bins. The number of empty bins should be about  , where
, where  is the number of balls. Hence
is the number of balls. Hence  . Solving this gives us the formula he recommends using:
. Solving this gives us the formula he recommends using:  .
. ,
, is the number of bins and
is the number of bins and  as
as  .
. as you can see
as you can see  , where
, where  represents
represents  , against the line
, against the line  . The difference between the two graphs represents the difference between
. The difference between the two graphs represents the difference between 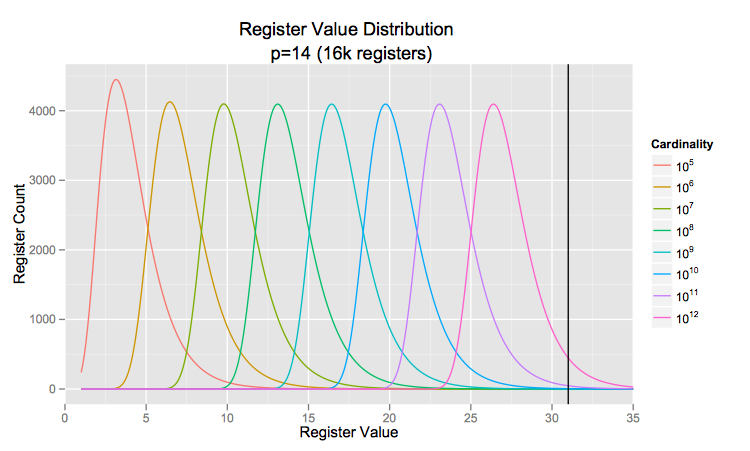
 .
. . Let’s says we wanted to safely count into the 100 billion range. If we have
. Let’s says we wanted to safely count into the 100 billion range. If we have  then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at
then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at  the large range correction only kicks in at a little under 100 billion!
the large range correction only kicks in at a little under 100 billion!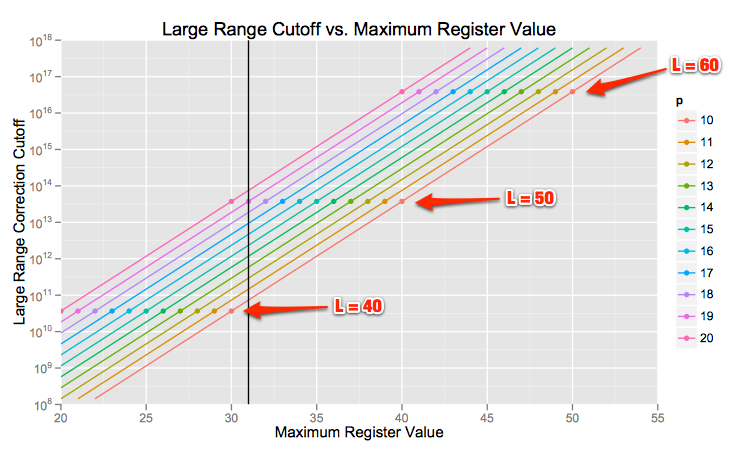
 configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space.
configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space. , for 200 values less than
, for 200 values less than  with a correction to the overestimate of
with a correction to the overestimate of 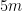 cardinality range (cuts 95th percentile relative error from about 2% to 1.2%).
cardinality range (cuts 95th percentile relative error from about 2% to 1.2%). . (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “
. (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “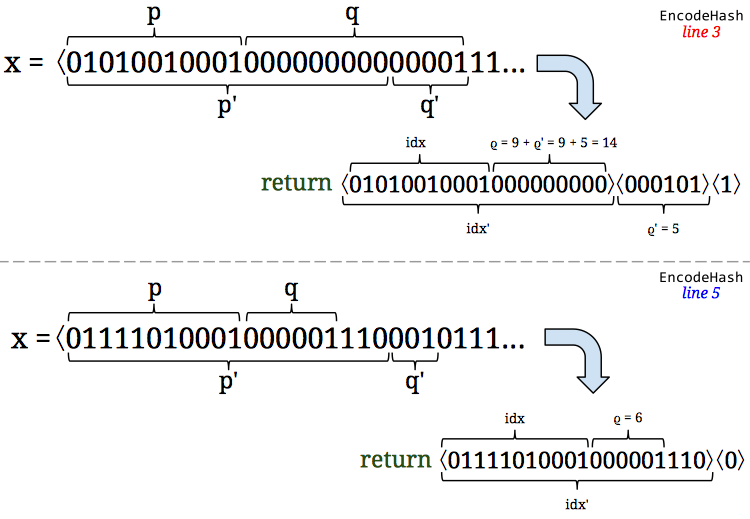
 are as in the Google paper, and
are as in the Google paper, and  and
and  are the number of bits that need to be examined to determine
are the number of bits that need to be examined to determine  for either the
for either the 
 is the register value and
is the register value and  is the number of (distinct) elements a register has seen.
is the number of (distinct) elements a register has seen. and say we insert
and say we insert 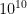 distinct elements. That means, any given register will see about
distinct elements. That means, any given register will see about  elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
 . So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,
. So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,  .
. and
and .
.![[15,40]](https://s0.wp.com/latex.php?latex=%5B15%2C40%5D&bg=ffffff&fg=000&s=0&c=20201002) . Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers.
. Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers.









