On Thursday, Nov. 13th I was given the opportunity to speak at AWS re:Invent 2014 about the ad analytics products and platforms we’ve built on Redshift. My slides are available here along with what I said in the speaker’s notes.
I covered how to implement four classical ad tech queries:
- Frequency – how many ads should I show each user?
- Attribution – how much should I pay for each ad?
- Overlap – where can I find these people for cheaper?
- Ad-hoc – how can I empower my users to run their own custom queries?
I also discussed how to take maximum advantage of Redshift’s simple orchestration and provisioning to scale to as many workloads and platforms as your heart desires and save money in the process!
It was a pleasure, as usual, to present to a packed room and to discuss all the great things the team has been up to.
 8xlarge should be “worth”
8xlarge should be “worth”  xlarge instances. (I test
xlarge instances. (I test  here.)
here.)






 and the other with
and the other with  , and wanted to compute their union. You could just follow my colleague Chris’
, and wanted to compute their union. You could just follow my colleague Chris’ 

 bits for your register index. That way you could just truncate the last 4 bits of the index and know that your register value would still be the same. On the other hand, if you’re Google, that may not be true. In that case, what you should do is use the
bits for your register index. That way you could just truncate the last 4 bits of the index and know that your register value would still be the same. On the other hand, if you’re Google, that may not be true. In that case, what you should do is use the 

 and register width of 6 (aka the heat death of the universe).
and register width of 6 (aka the heat death of the universe).

 is greater than
is greater than  . In this regime, they replace the usual HLL estimate by the estimate
. In this regime, they replace the usual HLL estimate by the estimate .
. -bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate
-bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate  empty bins. The number of empty bins should be about
empty bins. The number of empty bins should be about  , where
, where  is the number of balls. Hence
is the number of balls. Hence  . Solving this gives us the formula he recommends using:
. Solving this gives us the formula he recommends using:  .
. ,
, is the number of bins and
is the number of bins and  as
as  .
. as you can see
as you can see  , where
, where  represents
represents  , against the line
, against the line  . The difference between the two graphs represents the difference between
. The difference between the two graphs represents the difference between 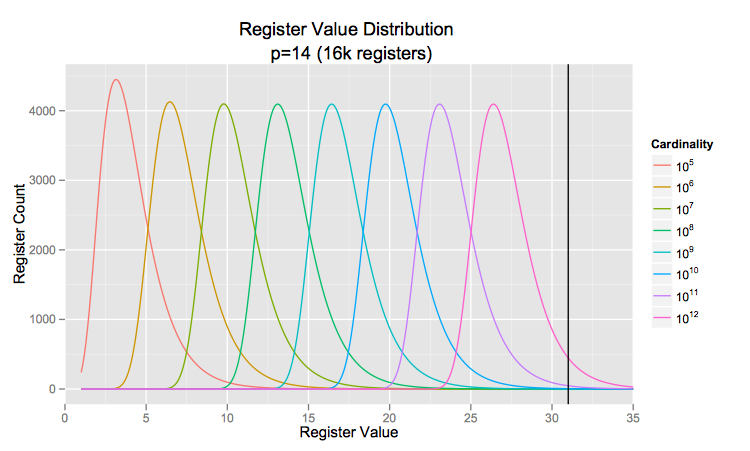
 .
. . Let’s says we wanted to safely count into the 100 billion range. If we have
. Let’s says we wanted to safely count into the 100 billion range. If we have  then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at
then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at  the large range correction only kicks in at a little under 100 billion!
the large range correction only kicks in at a little under 100 billion!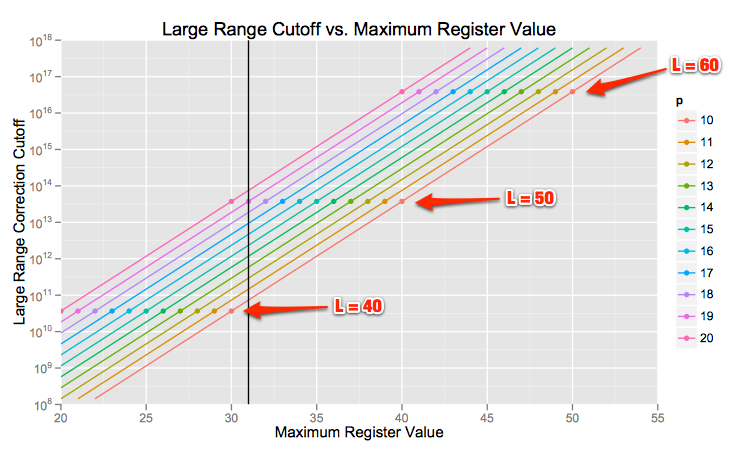
 configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space.
configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space. , for 200 values less than
, for 200 values less than  with a correction to the overestimate of
with a correction to the overestimate of 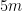 cardinality range (cuts 95th percentile relative error from about 2% to 1.2%).
cardinality range (cuts 95th percentile relative error from about 2% to 1.2%). . (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “
. (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “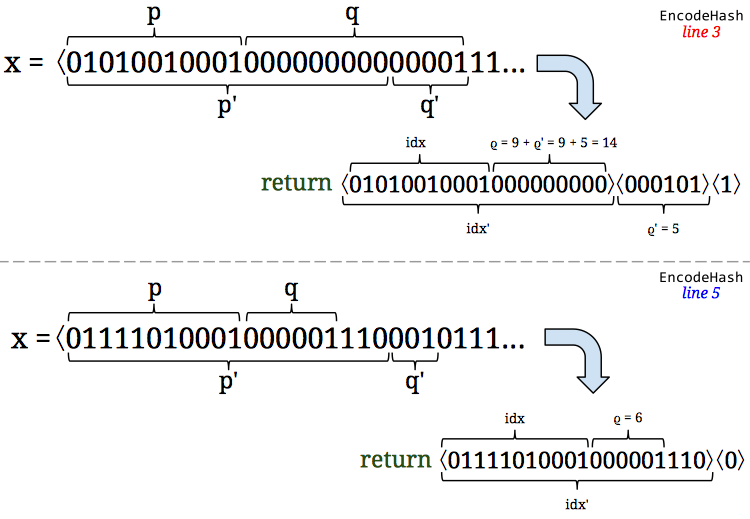
 are as in the Google paper, and
are as in the Google paper, and  and
and  are the number of bits that need to be examined to determine
are the number of bits that need to be examined to determine  for either the
for either the 
 is the register value and
is the register value and  is the number of (distinct) elements a register has seen.
is the number of (distinct) elements a register has seen. and say we insert
and say we insert 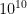 distinct elements. That means, any given register will see about
distinct elements. That means, any given register will see about  elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
 . So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,
. So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,  .
. and
and .
.![[15,40]](https://s0.wp.com/latex.php?latex=%5B15%2C40%5D&bg=ffffff&fg=000&s=0&c=20201002) . Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers.
. Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers.