I had the pleasure of speaking at the SF PostgreSQL User Group’s meetup tonight about sketching, the history of HLL, and our implementation of HLL as a PG extension. My slides are embedded below and you can get a PDF copy here. Be sure to click the gear below to show speaker’s notes for context!
If video is made available, I’ll post an update with a link!

 , which is chosen as a function of the expected cardinality to approximate. We track a great number of different cardinality streams and in this context it is useful for us to not have one fixed value of
, which is chosen as a function of the expected cardinality to approximate. We track a great number of different cardinality streams and in this context it is useful for us to not have one fixed value of  , then in an HLL that used a three-bit index, the same hashed value could have been placed in the bin whose index is either
, then in an HLL that used a three-bit index, the same hashed value could have been placed in the bin whose index is either 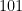 or
or  . Since
. Since  bins.The
bins.The 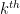 bin has the value 7 in it, and after doubling we guess that its partner bin, at index
bin has the value 7 in it, and after doubling we guess that its partner bin, at index  , should have a 5 in it. It is equally likely that the
, should have a 5 in it. It is equally likely that the  bin should have the 7 in it (since the “missing” prefix bit could have been a 1 or a 0)! Certainly the arrangement doesn’t change the basic cardinality estimate, but once we start getting involved with unions, the arrangement can make a very large difference.
bin should have the 7 in it (since the “missing” prefix bit could have been a 1 or a 0)! Certainly the arrangement doesn’t change the basic cardinality estimate, but once we start getting involved with unions, the arrangement can make a very large difference.

 bins, the value would have been placed in the first
bins, the value would have been placed in the first 
 cache value means that the 2 “belongs” in the top half of the large HLL, i.e. if we had processed the stream using a larger HLL the 2 would be in the same register. Essentially this cached bit allows you to know exactly where the largest value in a bin was located in the larger HLL (if the
cache value means that the 2 “belongs” in the top half of the large HLL, i.e. if we had processed the stream using a larger HLL the 2 would be in the same register. Essentially this cached bit allows you to know exactly where the largest value in a bin was located in the larger HLL (if the 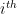 bin has value
bin has value  and cached value
and cached value  , we place the value
, we place the value  =
=  bin).
bin).
 in our bins. Thus, a standard HLL with
in our bins. Thus, a standard HLL with 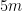 bits. Hence, this algorithm requires
bits. Hence, this algorithm requires  bits (with the extra
bits (with the extra 
 and comparing it to a folded HLL starting from
and comparing it to a folded HLL starting from  and folded down
and folded down 

 , keep track of whether
, keep track of whether  has shown up.)
has shown up.)
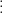


 and estimates the cardinality of the set quite well. You might have also observed that the most-significant (left-most) 1 can also be used for an estimator for the cardinality but it isn’t as clear-cut. This value is exactly the observable used in LogLog, SuperLogLog and HyperLogLog and does in fact lead to the larger relative error of
and estimates the cardinality of the set quite well. You might have also observed that the most-significant (left-most) 1 can also be used for an estimator for the cardinality but it isn’t as clear-cut. This value is exactly the observable used in LogLog, SuperLogLog and HyperLogLog and does in fact lead to the larger relative error of  (in the case of HLL).
(in the case of HLL).
 ) which can be dealt with by introducing corrections but they leave it as an exercise for the reader to determine what those corrections are. Scheuermann et al. did the leg work in
) which can be dealt with by introducing corrections but they leave it as an exercise for the reader to determine what those corrections are. Scheuermann et al. did the leg work in  ) is slightly deceiving in that
) is slightly deceiving in that 







 and the other with
and the other with  , and wanted to compute their union. You could just follow my colleague Chris’
, and wanted to compute their union. You could just follow my colleague Chris’ 

 bits for your register index. That way you could just truncate the last 4 bits of the index and know that your register value would still be the same. On the other hand, if you’re Google, that may not be true. In that case, what you should do is use the
bits for your register index. That way you could just truncate the last 4 bits of the index and know that your register value would still be the same. On the other hand, if you’re Google, that may not be true. In that case, what you should do is use the 

 and register width of 6 (aka the heat death of the universe).
and register width of 6 (aka the heat death of the universe). and an HLL
and an HLL  with
with bins and
bins and 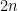 bins, respectively. Then we check what proportion of bins in
bins, respectively. Then we check what proportion of bins in  , agree with the bins in
, agree with the bins in  bins, and filling them in with the value in the corresponding bins in
bins, and filling them in with the value in the corresponding bins in 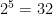 and one of size
and one of size  ), ran 200K keys through them, doubled the smaller one (according to
), ran 200K keys through them, doubled the smaller one (according to 







 is greater than
is greater than  . In this regime, they replace the usual HLL estimate by the estimate
. In this regime, they replace the usual HLL estimate by the estimate .
. -bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate
-bit hash. Each distinct value is a ball and each bin is designated by a value in the hash space. Hence, you “randomly” drop a ball into a bin if the hashed value of the ball corresponds to the hash value attached to the bin. Then, if we get an estimate  empty bins. The number of empty bins should be about
empty bins. The number of empty bins should be about  , where
, where  . Solving this gives us the formula he recommends using:
. Solving this gives us the formula he recommends using:  .
. ,
, as
as  .
. as you can see
as you can see  , where
, where  represents
represents  , against the line
, against the line  . The difference between the two graphs represents the difference between
. The difference between the two graphs represents the difference between 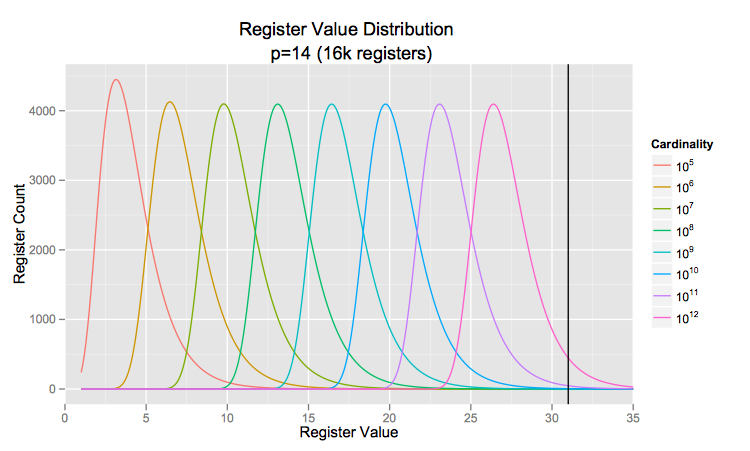
 .
. . Let’s says we wanted to safely count into the 100 billion range. If we have
. Let’s says we wanted to safely count into the 100 billion range. If we have  then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at
then our new “large range correction” boundary is roughly one trillion, per the adapted formula above. As you can see from the graph below, even at  the large range correction only kicks in at a little under 100 billion!
the large range correction only kicks in at a little under 100 billion!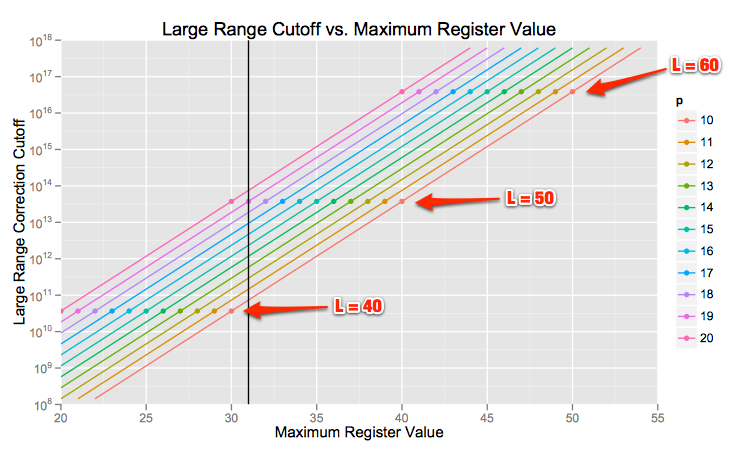
 configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space.
configuration range and found the relative error to be identical to that of lower cardinalities (in the millions of DVs). There’s really no reason to inflate the storage requirements for large cardinality HLLs by 20% simply because the hash space has expanded. Furthermore, you can do all kinds of simple tricks like storing an offset as metadata (which would only require at most 5 bits) for a whole HLL and storing the register values as the difference from that base offset, in order to make use of a larger hash space. with a correction to the overestimate of
with a correction to the overestimate of  . (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “
. (I’ll get to the leftover bit in a second!) This gives them increased precision which they can simply “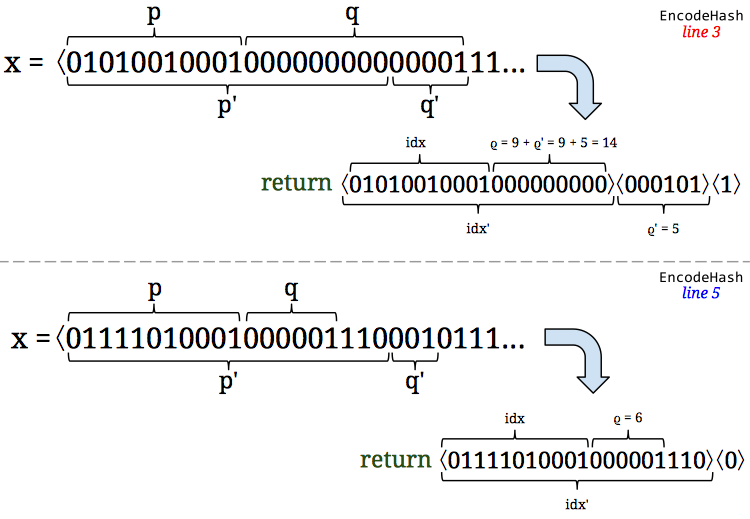
 are as in the Google paper, and
are as in the Google paper, and  and
and  are the number of bits that need to be examined to determine
are the number of bits that need to be examined to determine  for either the
for either the 
 is the number of (distinct) elements a register has seen.
is the number of (distinct) elements a register has seen. and say we insert
and say we insert 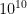 distinct elements. That means, any given register will see about
distinct elements. That means, any given register will see about  elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
elements assuming we have a decent hash function. So, the probability that a given register will have a value greater than 31 is (per the LogLog formula given above)
 . So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,
. So five registers out of sixteen thousand would overflow. I am skeptical that this would meaningfully affect the cardinality computation. In fact, I ran a few tests to verify this and found that the average number of registers with values greater than 31 was 4.5 and the relative error had the same standard deviation as that predicted by the paper,  .
. and
and .
.![[15,40]](https://s0.wp.com/latex.php?latex=%5B15%2C40%5D&bg=ffffff&fg=000&s=0&c=20201002) . Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers.
. Now I know that I can just store 15 in my offset and the true value minus the offset (which now fits in 5 bits) in the actual registers. ) allowing us to trivially estimate the distinct value count of any composition of streams without sacrificing precision or accuracy. This piqued our interest because if we can “losslessly” compute the union of two streams and produce low-error cardinality estimates, then there’s a chance we can use that estimate along with the
) allowing us to trivially estimate the distinct value count of any composition of streams without sacrificing precision or accuracy. This piqued our interest because if we can “losslessly” compute the union of two streams and produce low-error cardinality estimates, then there’s a chance we can use that estimate along with the  , and the set cardinalities that could inform our usage of HLL intersections in the AK product.
, and the set cardinalities that could inform our usage of HLL intersections in the AK product. .
. and their union
and their union  , then I’m going to call the intersection cardinality estimate produced
, then I’m going to call the intersection cardinality estimate produced  .
. .
. as a shorthand for the relative cardinality of the two sets.
as a shorthand for the relative cardinality of the two sets. as
as  .
. . A random stream of 64-bit integers hashed with
. A random stream of 64-bit integers hashed with  elements. We then built the corresponding HLLs
elements. We then built the corresponding HLLs  for those sets and calculated the intersection cardinality estimate
for those sets and calculated the intersection cardinality estimate  and computed its relative error.
and computed its relative error.")
 , register count has little effect on error, which stays very low.
, register count has little effect on error, which stays very low. , register count has little effect on error, which stays very high.
, register count has little effect on error, which stays very high. , and
, and .
.
 , then the error alone of
, then the error alone of 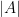 .
. by definition, so
by definition, so .
.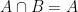 , the errors of
, the errors of  are both roughly the same size as what you’re trying to measure. Furthermore, even if
are both roughly the same size as what you’re trying to measure. Furthermore, even if  but the overlap is very small, then
but the overlap is very small, then  will be roughly as large as the error of all three right-hand terms.
will be roughly as large as the error of all three right-hand terms. and
and  ) and those that trivially do (
) and those that trivially do ( ) so we can focus more closely on the observations that are “on the bubble”. Sadly, these plots exhibit a good deal of variance inherent in their smaller sample size. Ideally we’d have tens of thousands of runs of each combination, but for now this rough sketch will hopefully be useful. (Apologies for the inconsistent colors between the two plots. It’s a real bear to coordinate these things in R.) Again, please click through for a larger, clearer image.
) so we can focus more closely on the observations that are “on the bubble”. Sadly, these plots exhibit a good deal of variance inherent in their smaller sample size. Ideally we’d have tens of thousands of runs of each combination, but for now this rough sketch will hopefully be useful. (Apologies for the inconsistent colors between the two plots. It’s a real bear to coordinate these things in R.) Again, please click through for a larger, clearer image.")
 , and
, and  a linear combination of those (independent) variables, we have
a linear combination of those (independent) variables, we have

 as in section 4 (“Discussion”) of the
as in section 4 (“Discussion”) of the  is not independent of
is not independent of  , though
, though 

 and
and  . Take a snapshot of the unique elements in those streams as sets and call them
. Take a snapshot of the unique elements in those streams as sets and call them  .
. then
then  .
.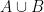 .
. then
then  .
.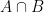 .
.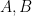 as above,
as above,  .
. .
. and
and  .
. .
. , which is also the same as the HLL created by taking the pairwise max of
, which is also the same as the HLL created by taking the pairwise max of  . (This is simply the inclusion-exclusion formula for two sets with the cardinality estimates instead of the true values.)
. (This is simply the inclusion-exclusion formula for two sets with the cardinality estimates instead of the true values.)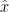 whose exact value is non-zero
whose exact value is non-zero  . That is, “by what percentage off the true value is the observation off?”
. That is, “by what percentage off the true value is the observation off?” then the relative error is
then the relative error is  .
.